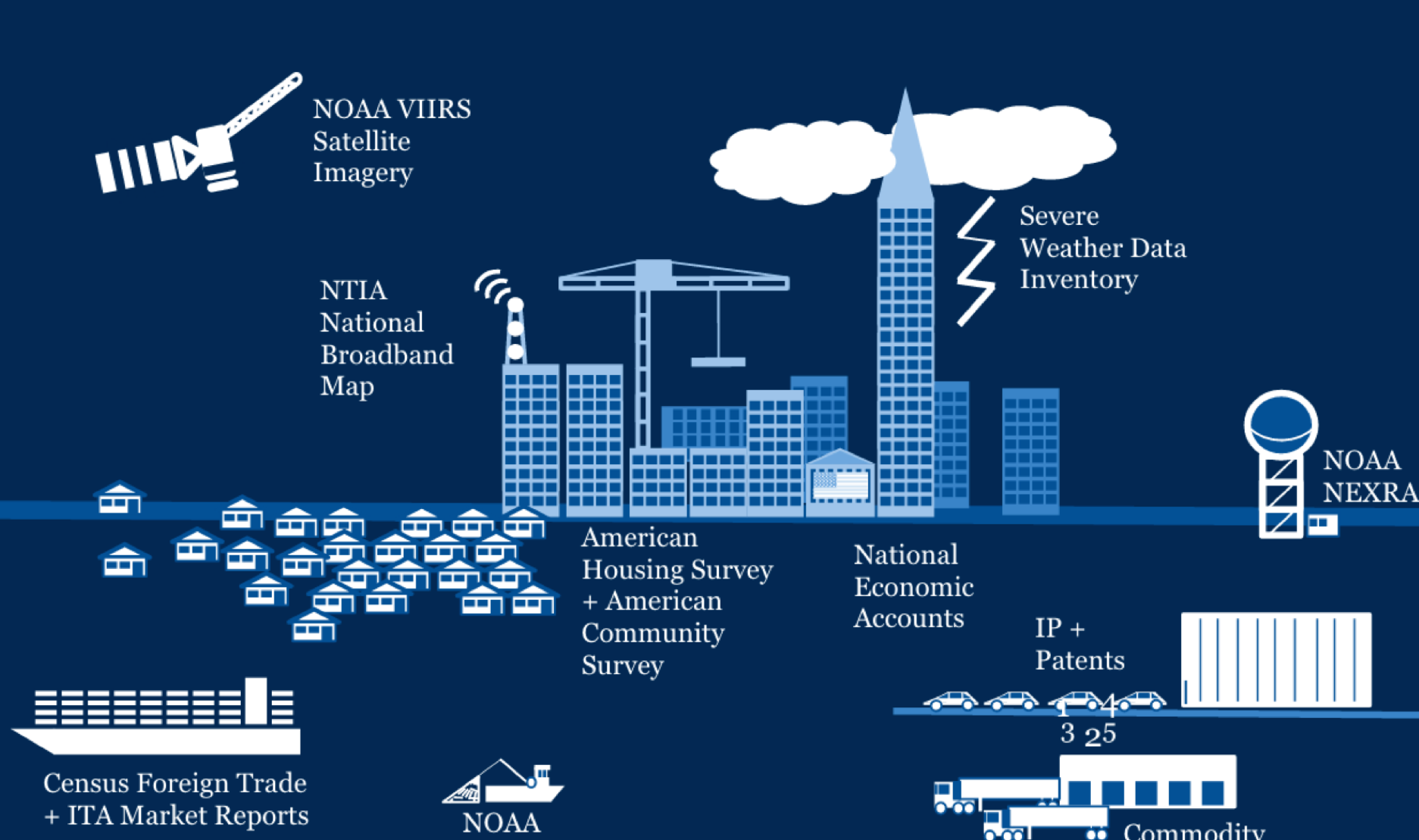
Satellite imagery holds the potential to understand society in unprecedented ways. Everytime a Low Earth Orbiting satellite like NASA's Aqua/Terra or the Suomi NPP completes an orbit every 90 minutes, we collect more data that could be used to proxy human processes as well as directly measure the environment. In fact, the VIIRS instrument on NPP produces 2.5 TB of data everyday that can fuel applications from gas flare monitoring to employment.
In my work with satellite imagery, I've been working to understand how social and economic indicators can be proxied using nighttime satellite imagery as well as used to support various research. In the case of predicting county-level employment using nighttime imagery, we find that the radiance distribution may hold clues as to how to treat varying levels of light. The same amount of light in a 350m x 350m square pixel in New York City may mean something entirely different in Las Vegas. Thus, much of my work focuses on understanding how highly dimensional representations of satellite imagery can be used to improve short-term prediction on local scales.
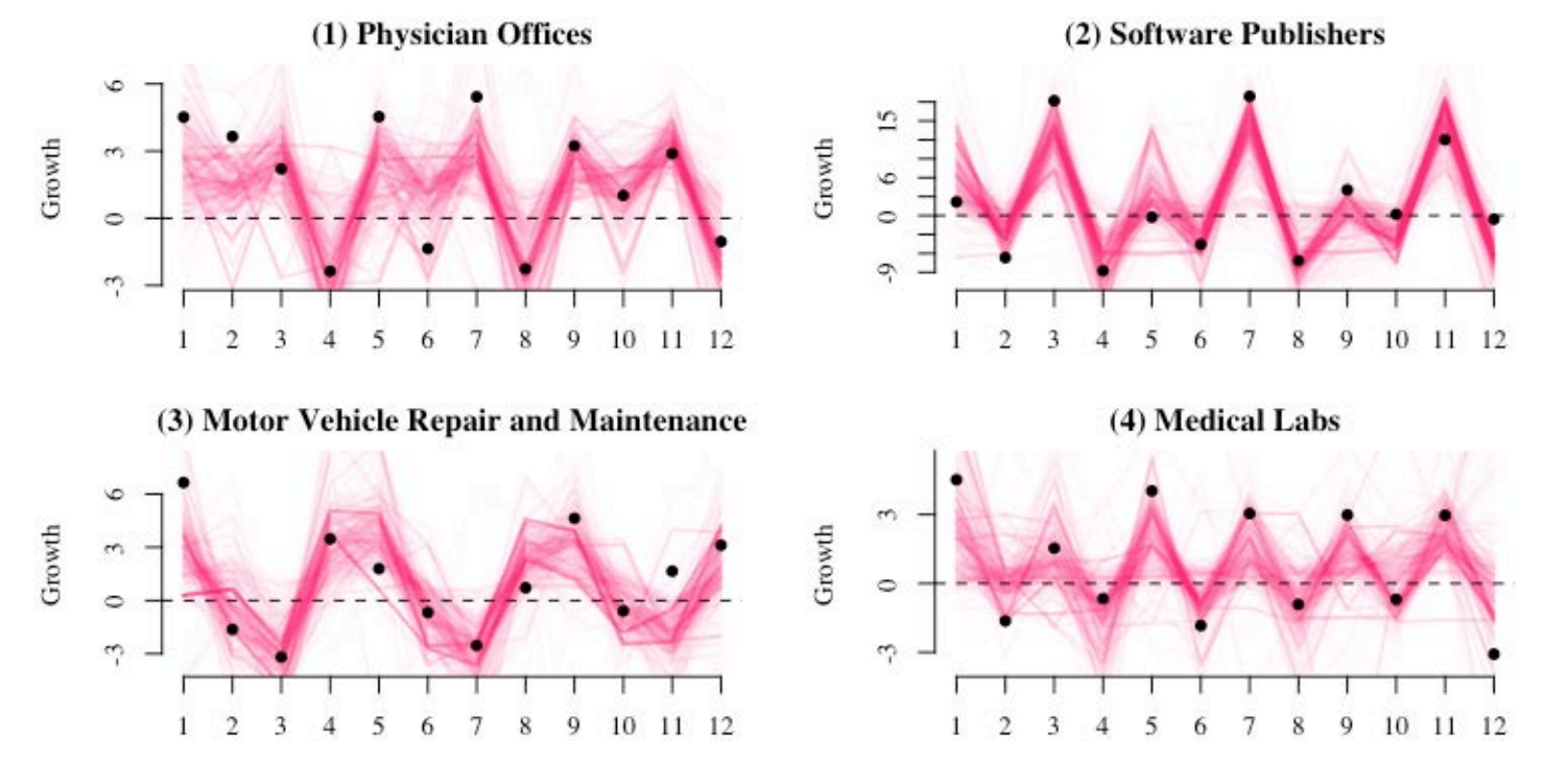
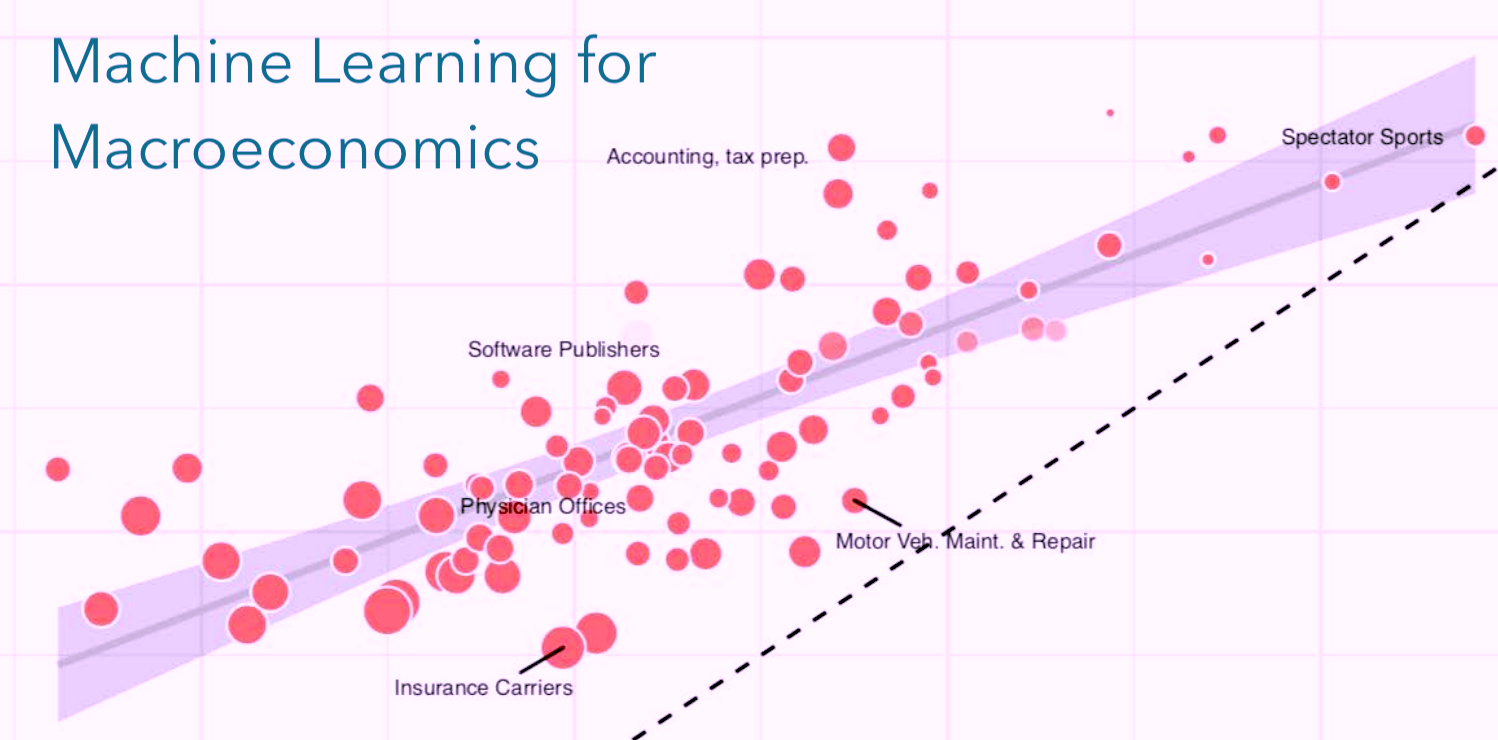
Machine Learning and Alternative Data are poised to make substantial improvements to macroeconomics and economic measurement. At BEA, I lead machine learning research to improve the accuracy of economic estimates and explore new sources of alternative data that can give us deeper insights into the digital economy.
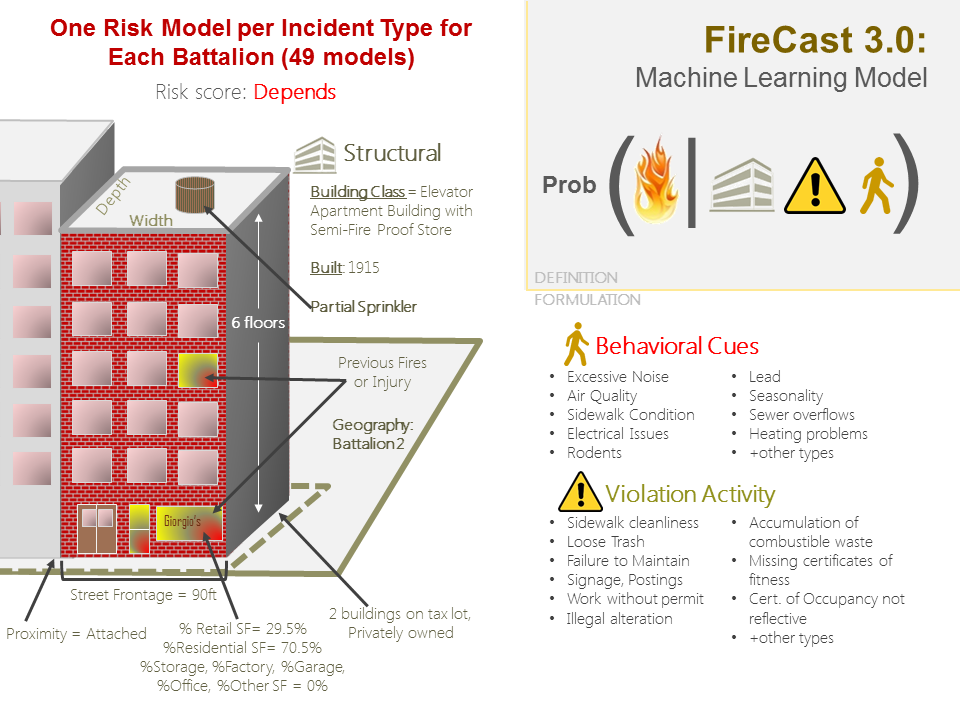
FireCast is a pioneering machine learning algorithm project developed in-house at FDNY. The approach screens 7,500 potential risk factors from across NYC government to find proxies that can help predict fires before they occur.
Fires are seemingly random, but there are clues as to why they happen and when to anticipate them. When visiting the scene of a recent incident, there may be attributes that would seem to be obvious precursors of a fire, but why wait for a fire to happen? FireCast was designed for emergency preparedness, that is, providing the field intelligence to fire companies to conduct building inspections. At the heart of it, FireCast is built on a basic spec:
Prob(Fire) = func(human activity, building characteristics, violation activity)
The rest of the algorithm is focused on geography-specific variable selection (e.g. battalions) combined with experimental design to prevent overfitting. As new risk trends emerge, FireCast is designed to capture them and reprioritize buildings for inspection. In short, billions of data elements captured in thousands of variables were tested in thousands of machine learning models tailored to each of FDNY's 49 battalions, allowing FDNY to pinpoint buildings of the highest risk of fire and ensure a safer New York through algorithmic awesomeness.
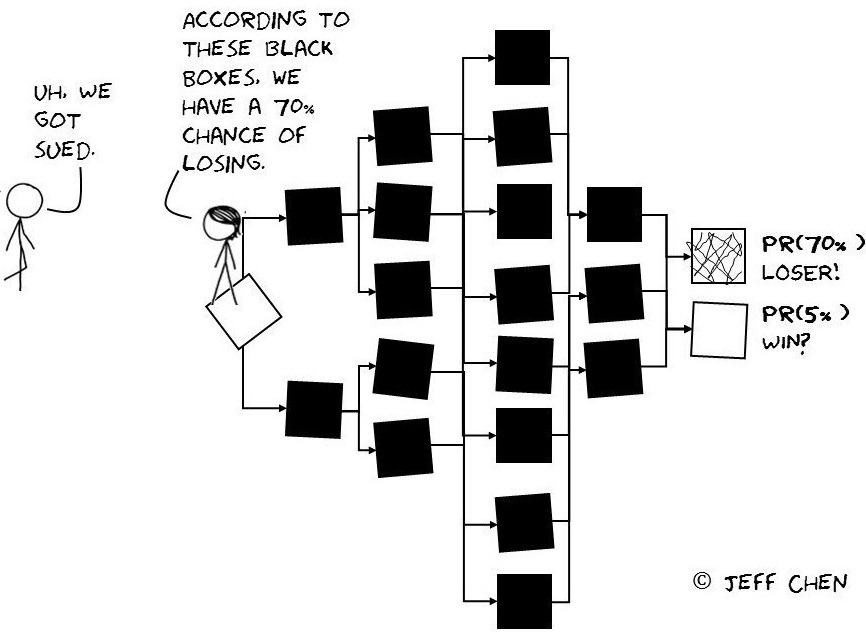
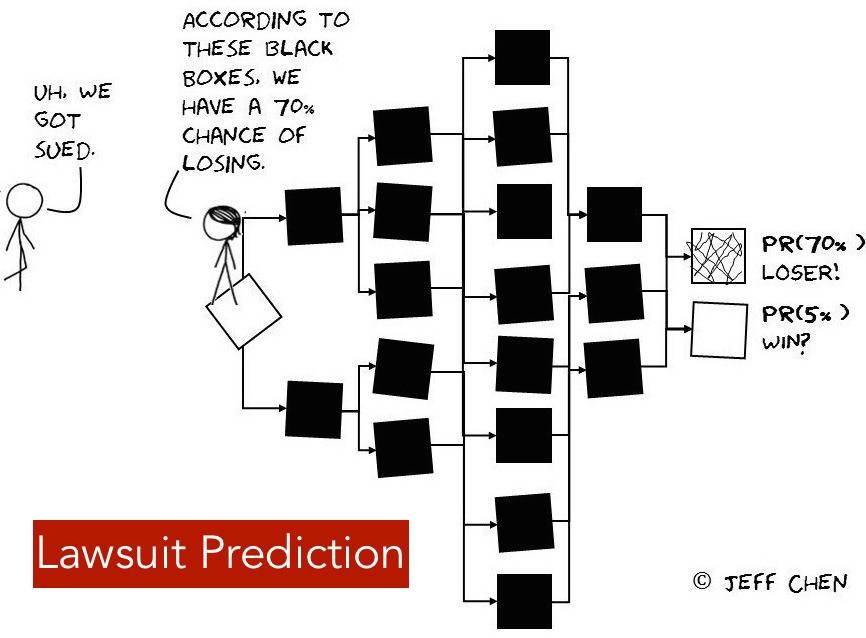
Agnostic of the evidence presented in a case, there are systematic quirks that are present regardless of the type of tort cases. Case characteristics such as time from the date of an incident and the date of filing the case, gender of the plaintiff, defendent type (e.g. corporation, person), individual lawyer caseload, type of incident, among other factors can help predict if a case will result in a payout. Using an ensemble of statistical classification methods, it's possible provide a reasonable sense of how a case will play out ahead of any hearing with predictive accuracies as high as 89%.
The devil is really in the details.
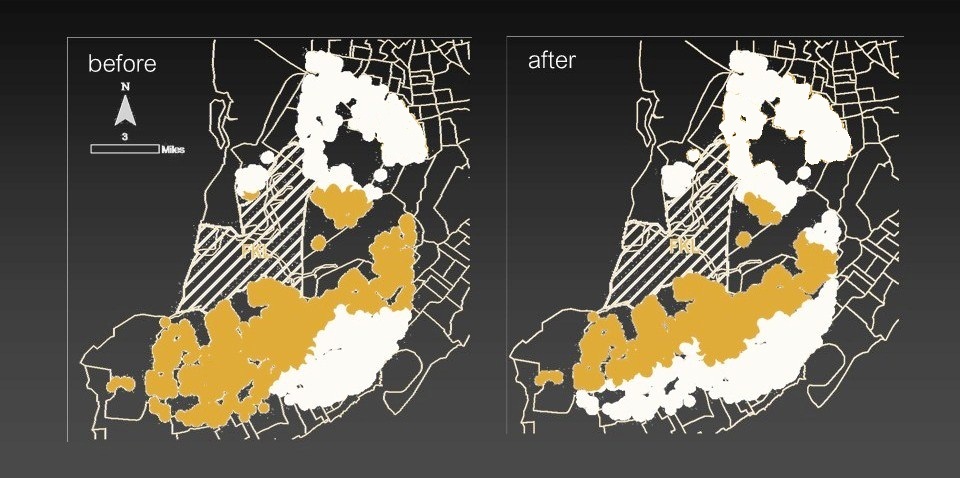
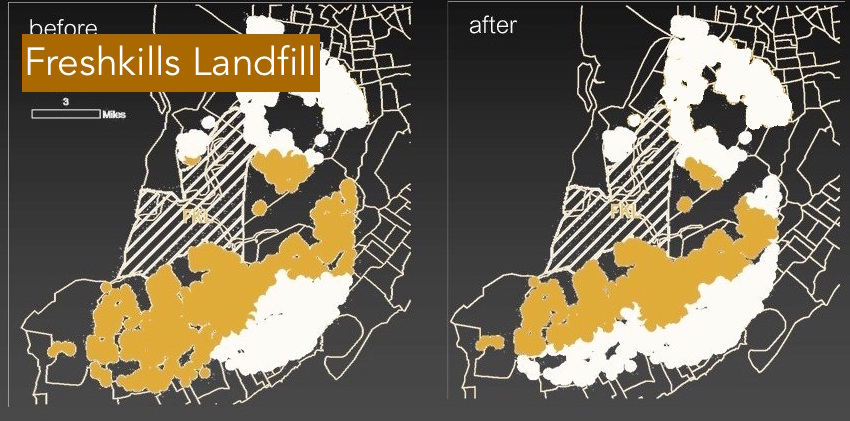
For nearly 50 years, Freshkills Landfill loomed over the western Staten Island landscape (NYC), eventually claiming the title of the world's largest landfill. Everyday, the landfill accepted enough municipal solid waste (MSW) to fill the field at Yankee Stadium two times over. By March 2001, the City of New York shut down the operation.
Freshkills was a local environmental externality due to its sensory impacts (e.g. sight and smell). The decomissioning of the site posed an opportunity to assess the extent of the site's externality influence and stigma. To understand directional stigma (e.g. lingering effects of externality), I developed a geographically weighted feature selection model to generalize hedonic pricing pre-post design framework at a micro-scale. If a dataset contained n = 32,000, this geographically weighted algorithm could be used to estimate a parameter surface over time for each hedonic variable, thereby allowing for some estimation of the presence of stigma. It's possible to use housing sales as a way to (1) calculate the distance and shape of the impact zone, and (2) determine changes to the price gradient -- that is houses closer to the site will likely have lower prices due to their proximity. Within three years, after the end of operations, about 20% of housing prices within a 2-mile radius of the landfill are no longer affected (see diagram above) and the price gradient has significantly 'flattened'.
The federal government has delivered hundreds of thousands of open datasets to the public. It's free and open. But, making data open is not enough. Data is not very useful without context, examples, narrative, code, questions. To close the gap, I've been the co-lead on a data education initiative called the Commerce Data Usability Project (CDUP) focused on closing the knowledge gap by furnishing the public with the basic knowledge behind the data. By working private industry, nonprofits and academia, long form tutorials are now being contributed by data scientists of all skill levels to build up a core knowledge base that makes data fundamentally useful and usable.
CDUP is aimed at the undergraduates, graduates, and research communities in order to bring value to those who need to learn and get started with research more efficiently. An economist who is interested in studying satellite data should be furnished with the know-how of how to ingest such data and use it. A non-profit strategy advisor should be able to use the US Census Bureau's American Community Survey to make more informed decisions for targeting services.
Hurricane Sandy left a destruction and hazards across New York City. While rapid scouting inspections conducted by building inspectors revealed the reach of the flood waters, little was known about the extent of damage and power systems.
Working with an interagency team, I co-led the design and implementation of rapid damage assessment and power restoration inspections in Staten Island. With an inspection force of over 100 personnel, in-depth physical inspections were undertaken at thousands of homes over a 96 hour blitz, informing citywide decision making.
Supporting the longer term recovery, I also wrote geocoding algorithms for Sandy impacted zone as well as developed classification algorithms for flagging uninspected homes with potential health risks (e.g. no heat, mold).